
大语言模型,从用户侧感知就是用户对大模型说一段话或者文本,大模型可以给一段有效的反馈,这段反馈是符合和一个人交流的结果,如下图所示就是大模型文本生成的过程。
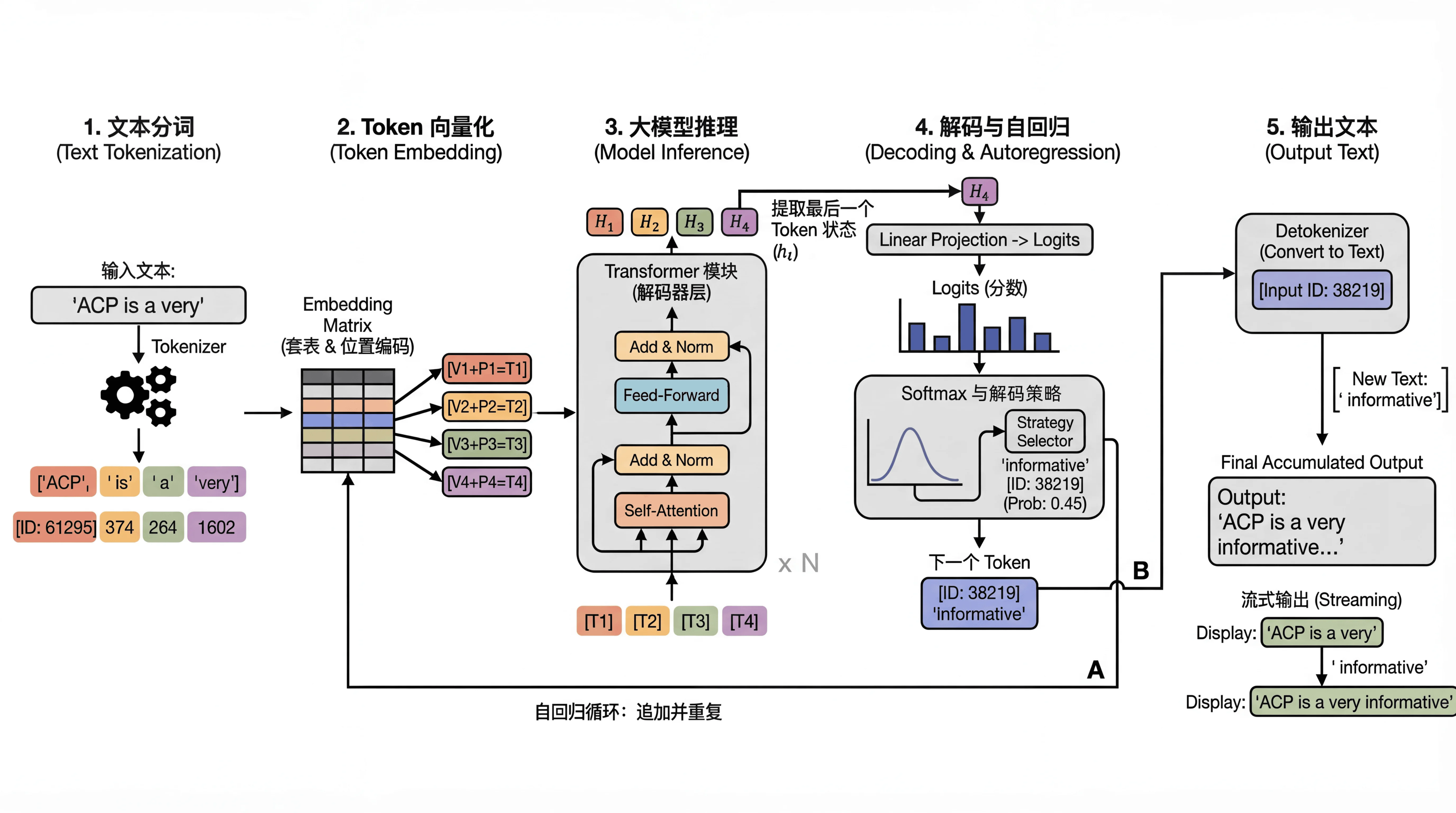
文本分词
计算机是无法理解复杂的文字的,我们需要把用户的输入转换成数字,这个过程就叫做分词,也就是Tokenization,Token是分词器把文本编码后得到的基本单元,每个token对应词表中的一个整数ID。不同的模型可能有自己不同的分词逻辑。
Token向量化
通过文本分词后得到了Token对应的数字ID,这些ID本身没有实际的意义,ID=100和ID=10不能说明什么,对计算机而言都是离散的数字,也无法识别ID=100和ID=10之间的关系是什么。为了让大模型能够理解,我们需要赋予这些数字更多维度的信息,在数学里面多维度的信息只能用向量来表示,我们需要把这个token在多维语义空间中的坐标绘制出来,这个过程就是Embedding。
语言的顺序也很关键,比如“你帮我”和“我帮你”,虽然字一样,但是顺序不一直语义完全不一直,所以我们需要为每个token添加位置信息,也就是PositionalEncoding。
大模型推理
携带了语义和位置信息的向量被送入Transformer模型的解码器进行计算,向量主城穿过数十个或者上百个结构相似的解码器,在因果注意力机制和前馈神经网络的作用下,文本向量中的信息被压缩和提取,得到一个分数向量。
解码与自回归
在得到分数向量后,我们需要计算每个向量被选中的概率,大模型会根据解码策略来选中要输出的token,解码策略有两类
①近似确定性解码:贪心解码,每次选择概率最高的token
②随机采样解码:从高概率候选集合中随机抽取
输出文本
最后系统会将整个过程中生成的token转换成人类可读的字符串,呈现给我们。
通过上面的分析,我们发现大模型的输出具有一定的随机性,这个随机也是可被调整的,即通过temperature和top_p来调整大模型next_token被选中的概率。
不同的temperature对token概率分布的影响
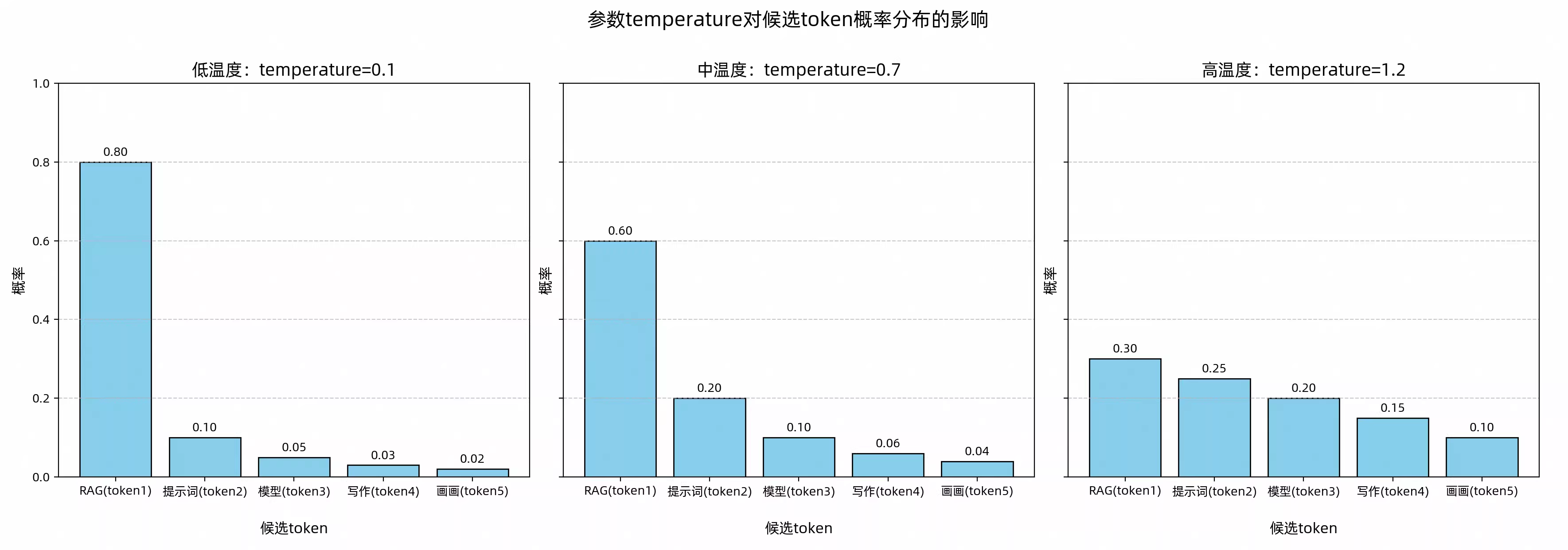
明确答案场景,如生成代码,调低温度;创意多样场景,如视频生成,调高温度;无特殊要求,使用默认温度。
top_p用来控制候选集合的采样范围,是一种筛选机制,用于从候选Token集合中选出符合特定条件的小集合,按概率从高到低排序,选取累计概率达到特定阈值的token组成新的候选集合,从而缩小选择范围。下图展示了不同top_p值对候选token集合采样的影响
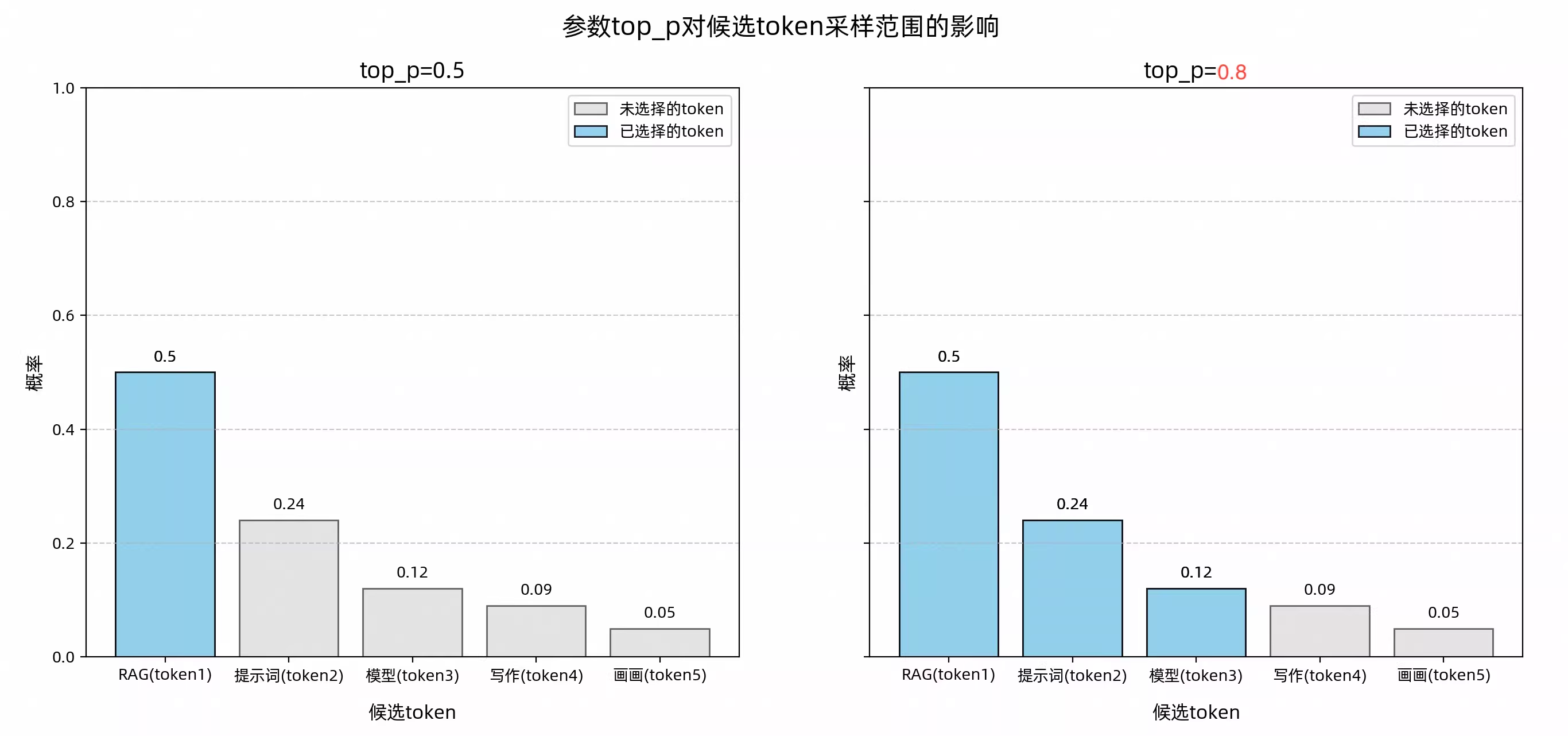
值越大,候选范围越广泛,内容更多样化,适合创意写作;值越小,候选范围越窄,输出更稳定,适合严谨场景;极小值,理论上模型只选择概率最高的token,输出非常稳定,但是实际上,由于分布式系统、模型输出的额外调整等罂粟可能还会存在微小随机性,无法保证每次输出完全一致。
temperature 和 top_p
temperature 和 to